Context rot
As AI-generated content feeds back into the organisation's context — documents, transcripts, summaries — today's hallucinations become tomorrow's training data, and the quality of the context degrades over time unless the cycle is actively broken.
Most discussions of AI failure treat context quality as a point-in-time property: the knowledge base is either good enough today or it is not. Context rot is a different kind of failure — one that unfolds over time as AI-generated content seeps back into the context that feeds the next round of AI work. Today’s hallucination, confidently phrased and filed alongside genuine material, becomes tomorrow’s training data. The organisation’s knowledge base gets progressively contaminated by its own AI’s errors, and the contamination is self-reinforcing.
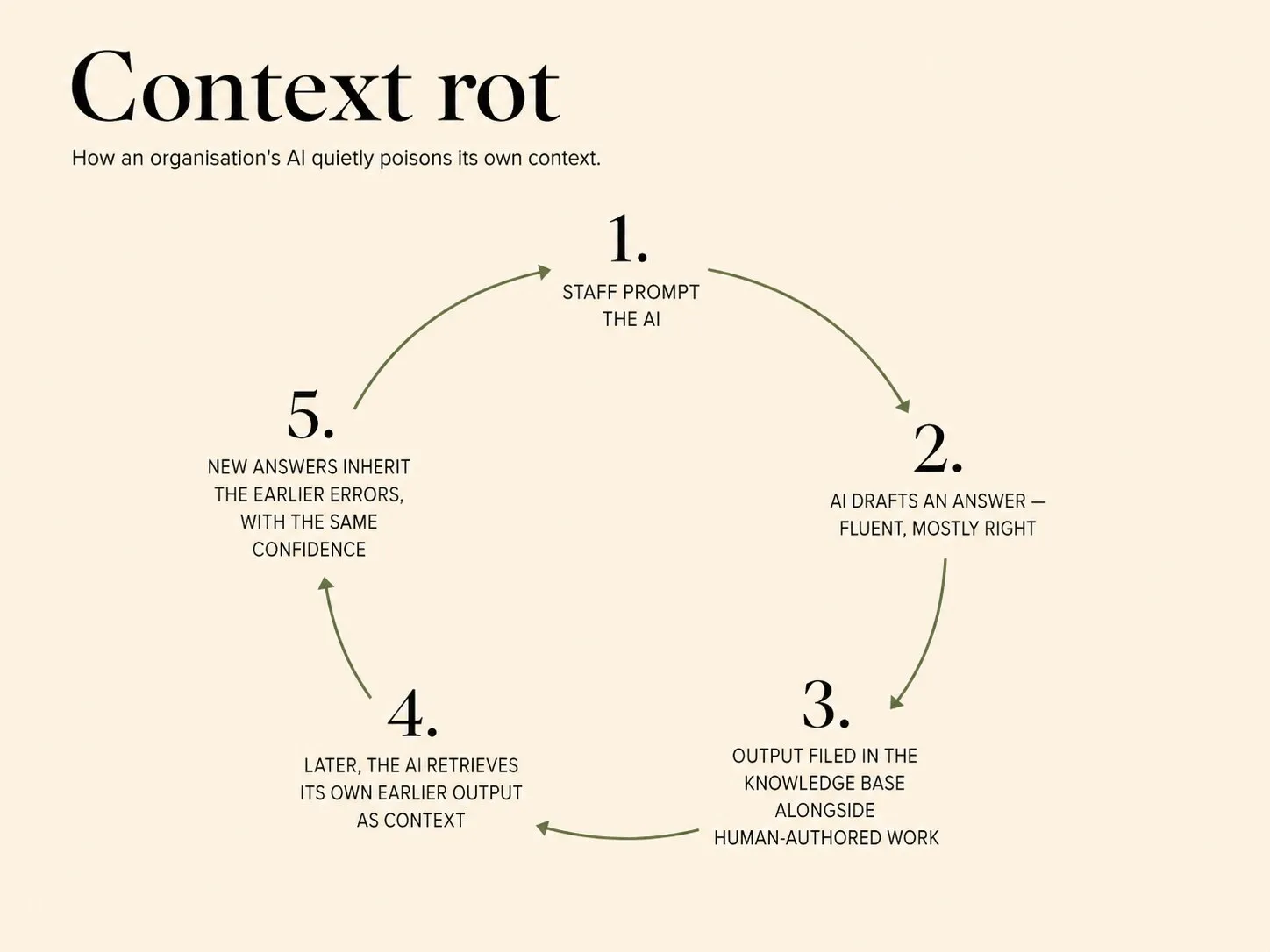
How the cycle works
The mechanics are ordinary. Staff use AI to draft a summary, a memo, a transcript analysis, a first-pass recommendation. The output is reviewed, mostly accepted, and stored in the same repository as the rest of the organisation’s documentation. Over months, a growing share of what the repository contains is AI-produced. When a future query draws on that repository, the AI is now reading its own earlier output as authoritative context. Errors that were generated once and missed at review are reinforced on every subsequent use.
The compounding is the dangerous part. A point-in-time context error can be caught and corrected. A time-dependent contamination distributes errors across many documents and many moments, so no single review catches more than a fraction. Meanwhile the AI treats the contaminated material with the same confidence it applies to everything else — see AI’s most dangerous failure mode is confident wrongness — so output that references the contaminated material looks as reliable as output that references genuine material. The distinction between the two is gradually lost.
What breaks the cycle
Breaking context rot is a governance problem, not a technical one. Three disciplines help.
Provenance. AI-generated content should be flagged as such in the repository, not quietly filed alongside human-authored material. When the AI later reads a document that says “this was AI-generated and reviewed on date X”, it treats that material differently from “this is the firm’s position on Y”.
Periodic audit. Sample AI-generated material in the knowledge base at regular intervals and re-verify it against current sources. The goal is not to catch every error but to refresh the reliability assumption and to identify patterns of error that reveal where the AI is drifting.
Ruthless pruning. The knowledge-management discipline set out in A document store is not a knowledge management system and Useful AI is a context problem applies with extra force when some of the material was AI-generated. Anything superseded should be removed. Anything that can be archived should be.
Why the pattern is only starting to matter
Context rot is recent because AI-generated content has only recently become a substantial share of what organisations retain. In 2023 it was a novelty; in 2026 it is a significant and growing fraction of most repositories. The compounding is not hypothetical; it is happening now, and organisations that treat their knowledge base as a neutral archive rather than an active governance surface will discover the cost eventually, as AI output quality declines on topics the firm thought it knew best.